Hi,
Ich wollte euch mal meinen Entwurf für das Handling der Playlisten vorstellen. Die Branch ist hier zu finden: https://github.com/laszloh/ESPuino/tree/devel/playlist_improvements
Die Branch ist mein Developemnt Branch ohne rebase & leanup, somit könnt ihr alle wundervollen blutigen Details und jedes einzelne Fail das ich auf dem Weg begegnet bin miterleben ![]()
Kurze Vorstellung des Systems
Die Klassenstruktur ist relativ einfach, es gibt eine abstrakte Klasse Playlist, die von allen anderen arten von Playlists implementiert werden. Die Playlist stellt einige Helper zur Verfügung, wie zB einen std-lib Memory-Allocator (der PSRAM bevorzugt) oder ein Sortier-Algorithmus für Strings. Durch die Vererbung haben alle Klassen zugriff darauf.
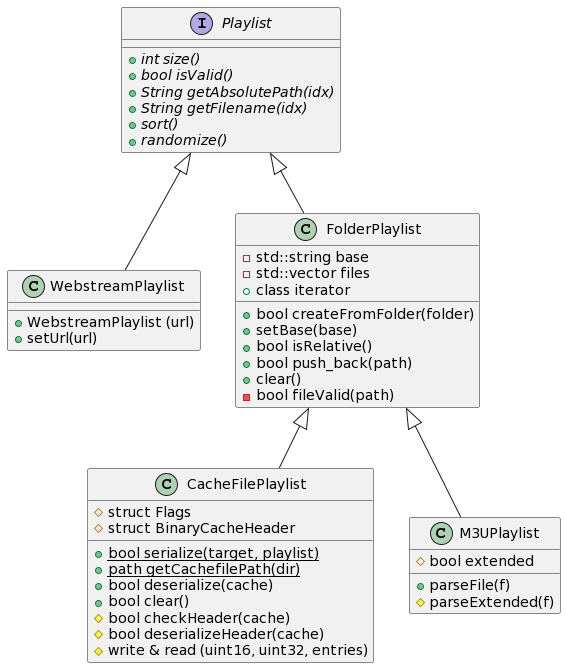
Es wird ein Pointer auf eine mit
new dynamisch alloktierte Playlist mit der Queue an den AudioPlayer_Task übergeben, der sich dadurch nicht mehr um die Implementierung im Hintergrund kümmern muss. Die Task ist für die Vernichtung der alten Playlist verantwortlich, sobald eine neue Playlist durch die Queue empfangen wird.
Einige Kommentare zu der Implementation, da wahrscheinlich da Fragen aufkommen werden ![]()
Verwendung von std::vector statt manueller Allokation
Wenn ihr in der Histroie schaut, war die erste Implementation vergleichbar zu unserer jetzigen Lösung mit manueller Allokation von Speicher für ein Array von char* Zeigern. Das funktioniert relativ gut, bis ich an den Punkt gekommen bin, dass ich den Pointer-Array auch vergrößern müssen könnte. Plus zwei Zählvariablen, eines für die Capacity und eines für die aktuelle Auslastung. An dem Punkt habe ich std::vector kurz aufgemacht und bemerkt, dass ich das gerade Rad neu erfinde…
Ich verwende std::vector mit einer initialen Größe von 64. Die GCC Version von std::vector implementiert ein Growth-Faktor von 2 (order 1.5), d.h. wenn der Allokierte Speicher ausgeht, wird dieser verdoppelt. Damit garantiert std::vector ein push_back mit amortisierende Faktor O(n). Damit sollten wir max 2-4 realloc’s benötigen (beim 4. hätten wir eine Playlist mit 1024 Einträgen). Das sollte reichen ![]()
Das spielt natürlich keine Rolle, wenn die Größe des Arrays zum Zeitpunkt des Aurufs bekannt ist, dann reserviere ich genau die nötige Größe vom Anfang an.
Ein riesen Plus, std::vector ruft beim Zerstören den Destruktur von jedem Eintrag im Array auf, damit müssen wir uns um ein Punkt weniger kümmern.
Verwendung von std::string
Der große Vorteil von std::string über String ist, dass ein Allokator definiert werden kann. Damit können wir std::string in den PSRAM verschieben, wenn dieser verfügbar ist. Der Allokator wird von std::string (eigentlich std::basic_string) verwendet, sobald dynamischer Speicher benötigt wird (sowol String als auch std::string haben einen internen Buffer, der bei Zeichenketten < ~10 Zeichen verwendet wird).
Vorteil über manuelles Arbeiten ist, dass sich schon jemand Gedanken um die Vernichtung des Speichers gemacht hat, d.h. sobald der Desktruktor von der Playlist aufgreufen wird, wird auch die std::string vernichtet.
Cache File
Das Handling der File habe ich geändert. Ich füge aktuell einen Header am Anfang ein, der neben der Anzahl an Einträgen, einem 16bit flag Feld auch, einer „magic Wert“ + Version hat (plus CRC um die Integrität zu erkennen). Das hat den Vorteil, dass wir automatisch veraltete Playlists erkennen können (also wenn sich zB die Struktur des Header oder die Anzahl/Position der Flags sich geändert hat) und entsprechend reagieren können.
Ein großer Nachteil dieser Lösung ist, dass wir nicht Rückwärtskompatibel sind. Die aktuelle SW stürzt mit einem Memory-Fehler ab, sobald versucht wird, den neuen Header zu lesen.
Ich spiele auch mit einer Idee, das Handling des Cache Files aus der Playlist zu extrahieren. Also ca solch eine Struktur:

Wehmutstropfen / Verbesserungpotenziale / Ideen
Ein großer schmerzhafter Punkt ist, dass die FreeRTOS Queues nicht c++ tauglich sind. Dadurch das wir mit xQueueSend einen POD (Plain Old Data) pointer übergeben, bin ich gezwungen mich manuell um die Allkation & Deallikation (mit new & delete) zu kümmern. Würden wir c++ Klassen übergeben können, könnten wird zB mit smart pointern arbeiten. Das würde uns einen weiteren Punkt von der Kopfschmerz liste streichen.
Ich hatte mir an dem Punkt überlegt, ob wir statt einer FreeRTOS-Queue einen einzelnen smart-pointer Objekt zu erstellen. Dieser würde, geschützt durch einem Semaphore, die Funktion der Queue übernehmen (die aktuell eh nur 1 Element tief ist).
Aktuell spiele ich mich aber noch mit dem Gedanken, diese Änderung auch einzubauen.
Unit Tests
Dank dem Klassensystem kann ich deren Funktion relativ einfach mit Unit Tests prüfen. Als Beispiel ist hier der Unit test von der FolderPlaylist: https://github.com/laszloh/ESPuino/blob/devel/playlist_improvements/test/test_filelist/test_main.cpp
Um die Tests durchzuführen, müsst ihr in VSCode das Chemie-Symbol drücken ().
![]()
Die ESP Tests laufen lokal auf dem ESP, dieser wird jeweils mit den einzelnen Test programmiert.
Wie immer sind Ideen gerne Willkommen ![]()